图像的阈值处理 demo1 # 二值化处理黑白渐变图 import cv2 img = cv2.imread("./img.png", 0) # 二值化处理 t1, dst = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) cv2.imshow("img", img) cv2.imshow("dst", dst) cv2.waitKey() cv2
图像的几何变换 demo1 # dsize实现缩放 import cv2 img = cv2.imread("./cat.jpg") dst1 = cv2.resize(img, (100, 100)) dst2 = cv2.resize(img, (400, 400)) # cv2.imshow("img", img) # cv2.imshow("dst1", dst1) # cv2.imsho
绘制图形和文字 demo1 # 绘制线段 import cv2 import numpy as np # 创建一个300×300 3通道的图像 canvas = np.ones((300, 300, 3), np.uint8)*255 # 绘制一条直线起点坐标为(50, 50)终点坐标为(250,50),颜色的BGR值为(255, 0, 0)(蓝色),粗细为5 canvas = cv2.line(
色彩空间和通道 demo1 import cv2 hsv_image = cv2.imread("./img.png") cv2.imshow("img", hsv_image) hsv_image = cv2.cvtColor(hsv_image, cv2.COLOR_BGR2HSV) h, s, v = cv2.split(hsv_image) cv2.imshow("B", h) cv2
open cv 入门 像素的操作 demo1 import cv2 import os import numpy as np # 1、读取图像 # imread()方法 # 设置图像的路径 Path = "./img.png" # 设置读取颜色类型默认是1代表彩色图 0 代表灰度图 # 彩色图 flag = 1 # 灰度图 #flag = 0 # 读取图像,返回值是一个图像对象 image
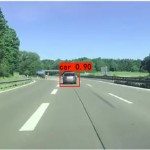
出处:https://blog.csdn.net/m0_66307842/article/details/128571685?spm=1001.2014.3001.5501作者:流继承 Ⅰ. 模版匹配和霍夫变换 0x00 模板匹配 原理所谓的模板匹配,就是在给定的图片中查找和模板最相似的区域,该算法的输入包括模板和图片,整个任务的思路就是按照滑窗的思路不断的移动模板图片,计算其与图像中对应区域
OpenCV基本操作主要介绍图像的基础操作,包括: 图像的IO操作,读取和保存方法 在图像上绘制几何图形 怎么获取图像的属性 怎么访问图像的像素,进行通道分离,合并等 怎么实现颜色空间的变换 图像的算术运算图像的基础操作学习目标 掌握图像的读取和保存方法 能够使用OpenCV在图像上绘制几何图形 能够访问图像的像素 能够获取图像的属性,并进行通道的分离和合并 能够实现颜色空间的变换 读
0. 简介 Camera与LiDAR之间的外部标定研究正朝着更精确、更自动、更通用的方向发展,由于很多方法在标定中采用了深度学习,因此大大减少了对场景的限制。然而,数据驱动方法具有传输能力低的缺点。除非进行额外的训练,否则它无法适应数据集的变化。随着基础模型的出现,这个问题可以得到显著缓解,通过使用分割任意模型(Segment Anything Model,SAM),我们这次提出了一种新的激光雷达
项目成果图 目标检测YOLOv5是一种计算机视觉算法,它是YOLO(You Only Look Once)系列算法的最新版本,由Joseph Redmon和Alexey Bochkovskiy等人开发。它是一种单阶段目标检测算法,可以在图像中检测出多个物体,并输出它们的类别和位置信息。相比于以往的YOLO版本,YOLOv5具有更高的检测精度和更快的速度 网络架构YOLOv5使用了一种新的检测架
概述与简介 RT-DETR是一种实时目标检测模型,它结合了两种经典的目标检测方法:Transformer和DETR(Detection Transformer)。Transformer是一种用于序列建模的神经网络架构,最初是用于自然语言处理,但已经被证明在计算机视觉领域也非常有效。DETR是一种端到端的目标检测模型,它将目标检测任务转换为一个对象查询问题,并使用Transformer进行解决。R
姿态识别技术是一种基于计算机视觉的人体姿态分析方法,可以通过分析人体的姿态,提取出人体的关键点和骨架信息,并对人体的姿态进行建模和识别。随着深度学习技术的发展,近年来姿态识别技术得到了广泛的应用和研究,其中Pose是一种基于深度学习的姿态识别工具包。本篇博客将介绍Pose的原理和方法,并探讨其在姿态识别领域的应用。目前识别手势,举左手 右手 双手 叉腰等姿态 一、 Pose的原理Pose是开发的
Python是一种非常流行的编程语言,具有广泛的应用领域,包括数据可视化。在数据可视化中,Python提供了多种工具来帮助用户创建各种类型的图表、图形和可视化效果。本文将介绍Python数据可视化的基本概念、工具和技术,并提供代码示例以说明如何使用Python进行数据可视化。 Python数据可视化基本概念数据可视化是将数据转换为图形或图表形式的过程,以帮助人们更好地理解和分析数据。Python
前言:为什么要重建纹理?为了真实感绘制,以及计算机的渲染。 1. 纹理图像的自动创建1.1 基础知识纹理贴图 1.2 算法流程 1.2 算法流程 1.2.2 纹理坐标的计算 1.2.3 全局颜色调整 1.2.4 泊松图像编辑 1.2.5 OBJ文件 1.3 结果示例 网
1. 三角化和体素重建的区别 基于“一致性”定义的不同,衍生出了多种方法,其中比较经典的包括: 1. 空间雕刻法,2. 体素着色法。 注意:基于体素的方法需要已知摄像机的内、外参数矩阵。 获取相机内外参数方法:1、SFM 计算得到2、固定工作台,相机和物体的位置关系进行标定2. 空间雕刻法 空间雕刻法的一致性定义给定工作体积中的一个点,将其投影到某个视图上时,如果投影点落在该视图的
项目是一个基于Python和OpenCV的交通标志检测和识别项目,旨在使用计算机视觉和深度学习技术对交通标志进行检测和分类。本文将从介绍项目原理和框架开始,详细介绍该项目的实现过程和技术细节,最后给出项目的安装和使用方法。 前后结果对比识别前 识别后 一、 项目原理和框架Traffic-Sign-Detection项目的主要原理是使用计算机视觉和深度学习技术对交通标志进行检测和分类。具体来说
1. 三维物体的表面表达方式✓ 边界表示法✓ 空间划分法✓ 构造体素法1.1 边界表示法 (Boundary Representation) 1.2 空间划分法 (Spatial-Partitioning Representations) 1.3 构造体素法 (Boundary Constructive Solid Geometry) 2. 三维模型的表述方式 3. 基于符号距离场的表面
pytorch的hook机制允许我们在不修改模型class的情况下,去debug backward、查看forward的activations和修改梯度。hook是一个在forward和backward计算时可以被执行的函数。在pytorch中,可以对Tensor和nn.Module添加hook。hook有两种类型,forward hook和backward hook。 1. 对Tensors添
引用库文件 import os from hobot_dnn import pyeasy_dnn as dnn from hobot_vio import libsrcampy as srcampy import numpy as np import cv2 import colorsys from time import ti
感受野可能是卷积神经网络中最重要的概念之一,在学术中也被广泛关注。几乎所有的目标检测方法都围绕感受野来设计其模型结构。这篇文章通过可视化的方法来表达感受野的信息,并且提供一用于计算任何CNN网络每一层感受野的程序。 对于CNN相关的基础知识,可以参考A guide to convolution arithmetic for deep learning。 首先看一下感受野的定义,感受野是指在输入
OpenCV中视频操作及人脸识别案例 主要内容:•视频文件的读取和存储•视频追踪中的meanshift和camshift算法•人脸识别案例 视频操作视频读写 学习目标•掌握读取视频文件,显示视频,保存视频文件的方法 从文件中读取视频并播放 在OpenCV中我们要获取一个视频,需要创建一个VideoCapture对象,指定你要读取的视频文件: 1.创建读取视频的对象 cap = c
第三方账号登入
看不清?点击更换




















第三方账号登入
QQ 微博 微信